Asumsi tes Chi-Square (independensi, ukuran sampel cukup)
Chi-Square menguji apakah ada hubungan antara dua variabel kategorikal
Melakukan tes Chi-Square dengan chisq.test()
Interpretasi statistik Chi-Square dan p-value
p-value < 0.05 berarti ada hubungan signifikan antara variabel
Membuat tabel kontingensi dengan table()
Cara melaporkan hasil Chi-Square dalam format ilmiah
Memvisualisasikan hasil dengan ggplot2
4.2 Latihan Retrieval & Pengantar
Latihan Retrieval: Sebelum mempelajari Chi-square, coba ingat kembali: - Apa perbedaan antara variabel kategorikal dan variabel numerik? - Berikan contoh variabel kategorikal dalam penelitian biologi! - Bagaimana cara menyajikan data kategorikal dalam tabel?
4.3 Apa itu Tes Chi-Square?
Tes Chi-Square of Independence membantu kita menjawab:
Apakah ada hubungan antara dua variabel kategorikal?
Atau apakah mereka independen?
Ini membandingkan frekuensi yang diamati (yang sebenarnya kita lihat) dengan frekuensi yang diharapkan (yang akan kita harapkan jika variabel-variabel tersebut tidak berhubungan).
4.3.1Hinge Question
Anda sedang meneliti apakah jenis tanah (lempung, berpasir, liat) mempengaruhi jenis tanaman yang tumbuh (bunga, sayur, pohon). Variabel apa yang kategorikal?
Hanya jenis tanah
Hanya jenis tanaman
Kedua variabel (jenis tanah DAN jenis tanaman)
Tidak ada variabel kategorikal
Jawaban: C. Kedua variabel adalah kategorikal — Chi-square test digunakan untuk menguji hubungan antara dua variabel kategorikal.
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
library(ggplot2)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(ggrepel)library(ggthemes)
4.4 Contoh: Penguin di Pulau
Mari kita lihat dataset penguin kita lagi. Bagaimana penguin terdistribusi di ketiga pulau?
4.4.1 Frekuensi yang Diamati (O)
df <-na.omit(penguins)# Buat tabel kontingensi yang diamatipenguin_table <-table(df$species, df$island)as.data.frame.matrix(penguin_table)
# Dapatkan totalrow_totals <-rowSums(penguin_table)col_totals <-colSums(penguin_table)grand_total <-sum(penguin_table)# Hitung manual matriks frekuensi yang diharapkanexpected_matrix <-outer(row_totals, col_totals, FUN =function(r, c) (r * c) / grand_total)# Bulatkan ke bilangan bulat terdekatexpected_matrix <-round(expected_matrix)# Berikan nama baris dan kolomrownames(expected_matrix) <-rownames(penguin_table)colnames(expected_matrix) <-colnames(penguin_table)# Lihat frekuensi yang diharapkanexpected_matrix
Mari bandingkan nilai yang diamati dan yang diharapkan side by side:
# Ekstrak yang diamati dan yang diharapkanobserved <-as.numeric(penguin_table)expected <-as.numeric(expected_matrix)# Gabungkan menjadi data frame dengan labelspecies <-rep(rownames(penguin_table), times =ncol(penguin_table))island <-rep(colnames(penguin_table), each =nrow(penguin_table))observation_table <-data.frame(Species = species,Island = island,Observed = observed,Expected =round(expected, 2))observation_table
Statistik tes Chi-Square memberi kita seberapa berbeda data yang diamati dari yang kita harapkan berdasarkan asumsi bahwa dua variabel kategorikal independen.
Kita menggunakan formula berikut:
\[\chi^2 = \sum \frac{(O - E)^2}{E}\]
Di mana:
\(( O )\) = frekuensi yang diamati (yang sebenarnya kita hitung)
\(( E )\) = frekuensi yang diharapkan (yang akan kita harapkan jika tidak ada asosiasi)
\(( \chi^2 )\) = statistik tes total, mengukur perbedaan keseluruhan antara yang diamati dan yang diharapkan
4.5.1 Bagaimana Cara Kerjanya?
Kita melewati setiap sel tabel kontingensi dan menghitung:
\[\frac{(O - E)^2}{E}\]
Nilai ini akan: - Dekat dengan 0 jika yang diamati dan yang diharapkan mirip - Lebih besar ketika ada perbedaan besar antara keduanya
Kemudian kita jumlahkan semua nilai ini dari setiap sel untuk mendapatkan statistik Chi-Square total.
4.5.2 Apa yang Dikatakannya?
Jika nilai \(( \chi^2 )\) yang dihasilkan cukup besar, ini berarti perbedaan antara yang diamati dan yang diharapkan terlalu besar untuk disebabkan oleh kebetulan acak.
Ini menunjukkan bahwa dua variabel (seperti spesies dan pulau) kemungkinan besar terkait.
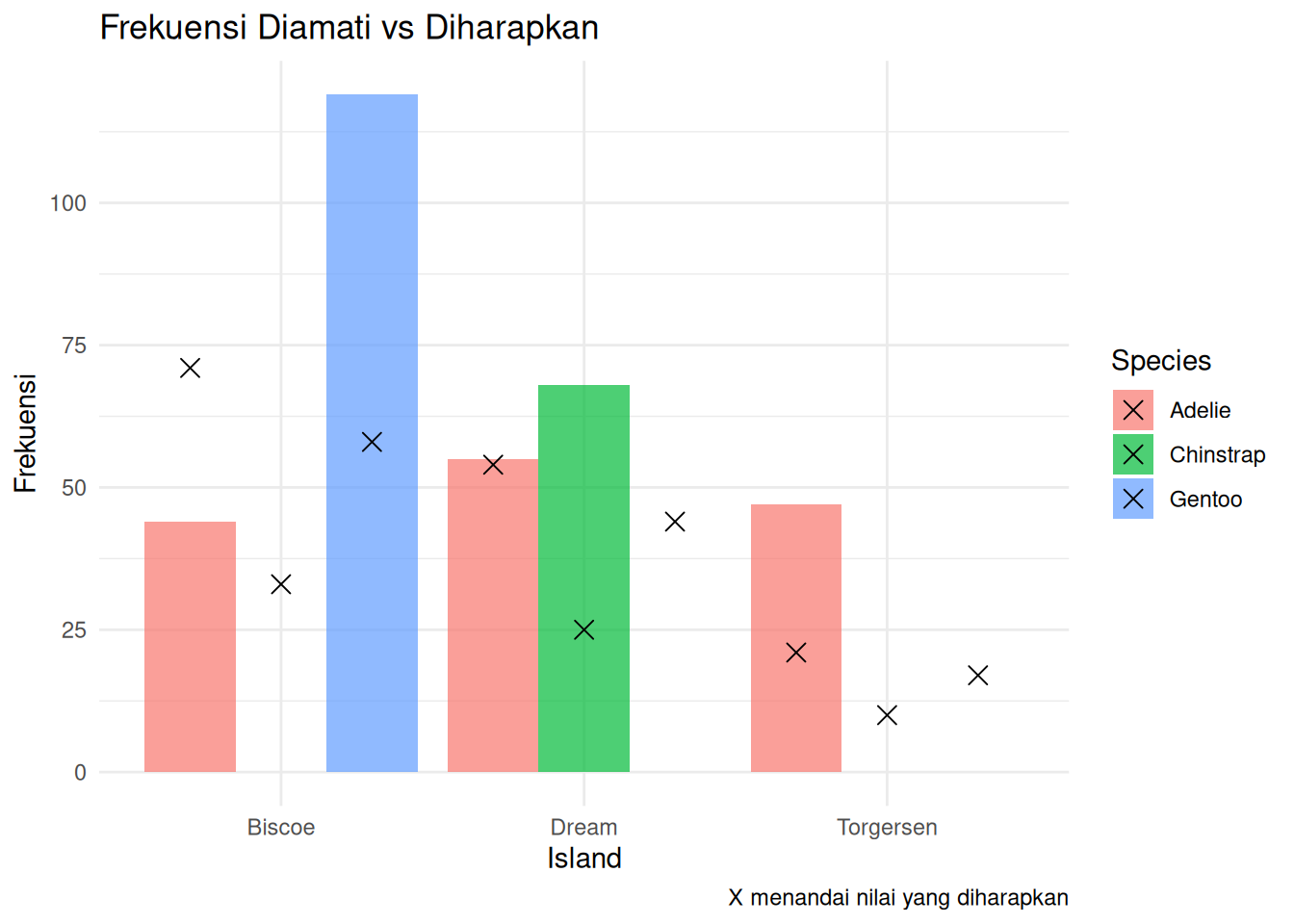
4.5.3 Visualisasi O vs E
Untuk membantu Anda lebih memahami dari mana perbedaan berasal, Anda dapat membuat bar plot yang membandingkan frekuensi yang diamati vs yang diharapkan:
ggplot(observation_table, aes(x = Island, fill = Species)) +geom_bar(aes(y = Observed), stat ="identity", position ="dodge", alpha =0.7) +geom_point(aes(y = Expected), shape =4, size =3,position =position_dodge(width =0.9)) +labs(title ="Frekuensi Diamati vs Diharapkan",y ="Frekuensi", caption ="X menandai nilai yang diharapkan") +theme_minimal()
4.5.4 Mari Hitung Nilai Chi-Square
Mari kita lewati setiap sel tabel kontingensi dan hitung:
\[\frac{(O - E)^2}{E}\]
Dan pada akhirnya, kita akan membuat penjumlahan dari semua nilai komponen
# Hitung komponen chi-square: (O - E)^2 / Ecomponent <- (observed - expected)^2/ expected# Tambahkan ke data frame (bulatkan jika diinginkan)observation_table$Component <-round(component, 2)# Lihat tabel yang diperbaruiobservation_table
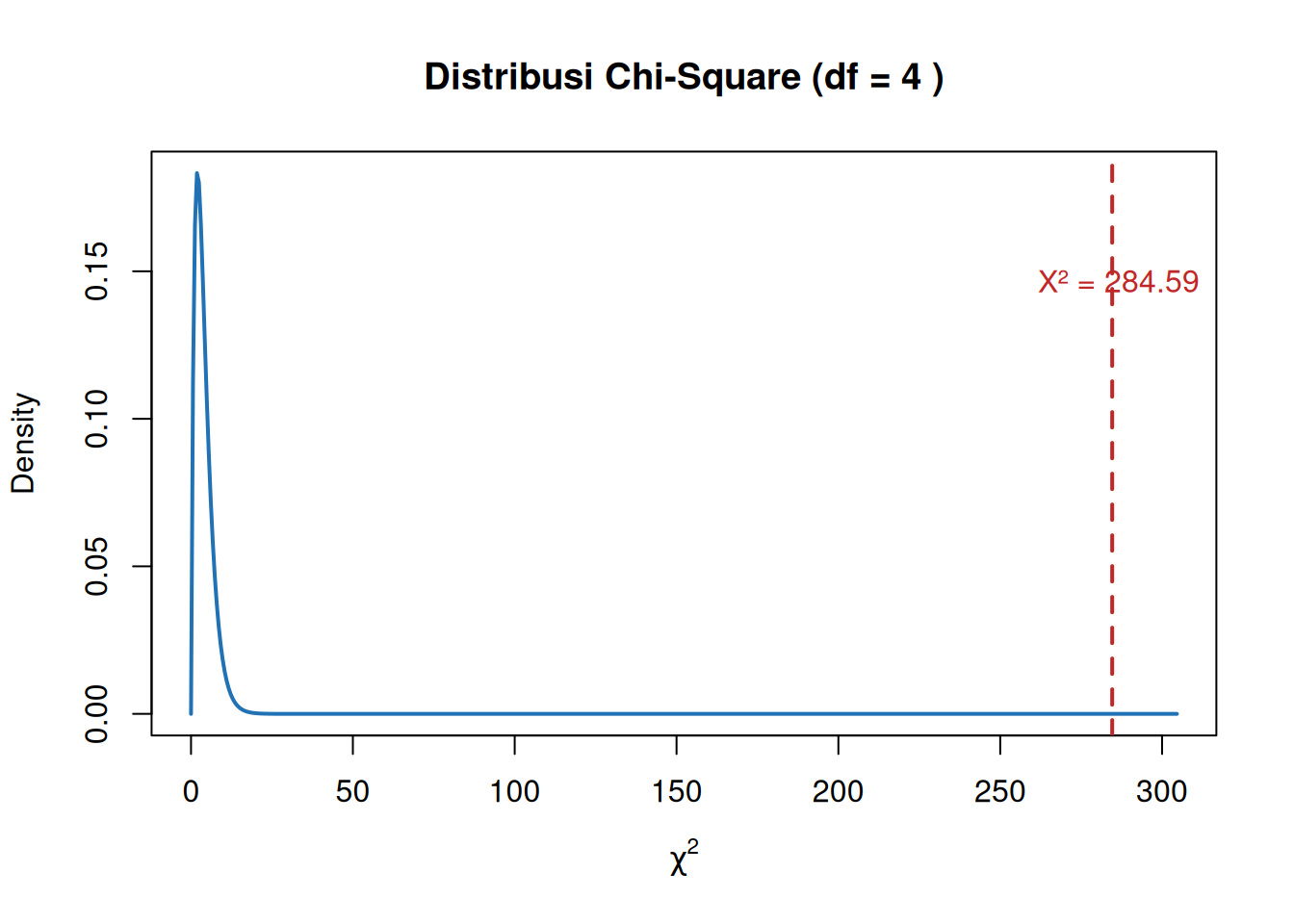
# Statistik chi-square totalcat("Total χ² =", round(sum(component), 2), "\n")
Total χ² = 284.59
4.5.5 Derajat Kebebasan
Jadi, kita mendapat nilai χ², tapi bagaimana kita menginterpretasikannya? Sebelum kita dapat menginterpretasikan nilai tersebut, pertama-tama kita perlu menghitung derajat kebebasan.
Derajat kebebasan (df) untuk tes Chi-Square dalam tabel kontingensi dihitung sebagai:
Dalam kasus kita, ada 3 spesies (baris) dan 3 pulau (kolom):
\[df = (3 - 1)(3 - 1) = 2 \times 2 = 4\]
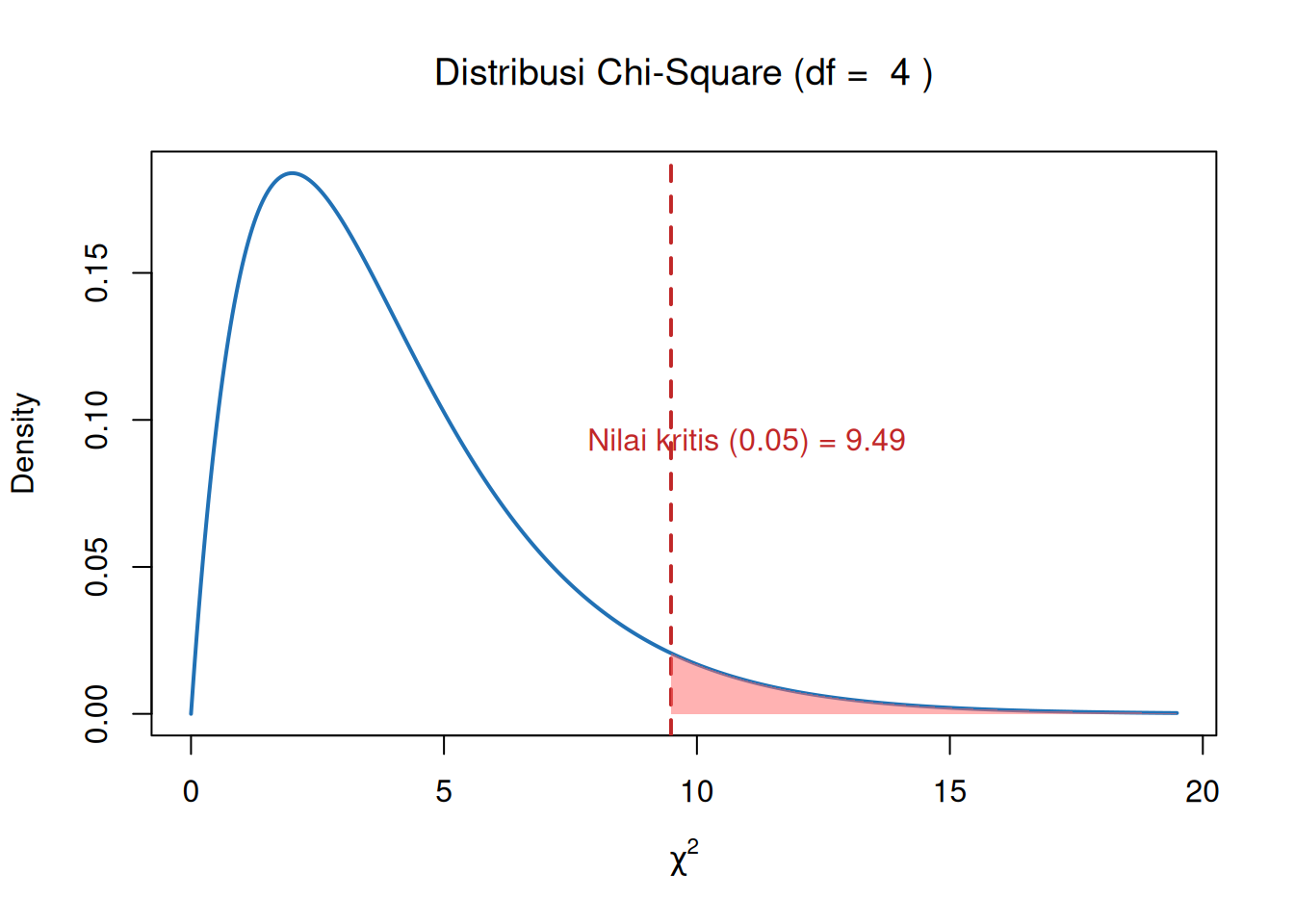
Kita dapat menggunakan df untuk menemukan nilai kritis dari tabel distribusi Chi-Square pada tingkat signifikansi 0.05.
# Parameterdf_val <-4alpha <-0.05# Nilai kritis (ambang batas right-tail)critical_value <-qchisq(p =1- alpha, df = df_val)# Generate x dan y untuk kurva densitas chi-squarex <-seq(0, critical_value +10, length.out =500)y <-dchisq(x, df = df_val)# Plot distribusi Chi-Squareplot(x, y, type ="l", lwd =2, col ="#2171B5",ylab ="Density", xlab =expression(chi^2),main =bquote("Distribusi Chi-Square (df = "~ .(df_val) ~")"))# Tambahkan garis vertikal di nilai kritisabline(v = critical_value, col ="#c02728", lwd =2, lty =2)# Bayangkan daerah penolakan (right tail)x_shade <-seq(critical_value, max(x), length.out =100)y_shade <-dchisq(x_shade, df = df_val)polygon(c(critical_value, x_shade, max(x_shade)),c(0, y_shade, 0),col ="#FF666680", border =NA)# Anotasi plottext(critical_value +1.5, max(y)*0.5,paste0("Nilai kritis (0.05) = ", round(critical_value, 2)),col ="#c02728")
4.5.6 Interpretasi
Sekarang kita membandingkan statistik Chi-Square yang dihitung dengan nilai kritis dari tabel distribusi Chi-Square pada tingkat signifikansi 0.05.
Jika:
\(( \chi^2 = 284.59 )\)
\(( df = 4 )\)
Nilai kritis pada \(( \alpha = 0.05 )\) adalah 9.49
Maka:
\[284.59 > 9.49\]
Jadi kita menolak hipotesis nol.
Kesimpulan:
- Ada hubungan secara statistik signifikan antara spesies penguin dan pulau tempat mereka ditemukan.
- Distribusi tidak seragam dan kemungkinan mencerminkan preferensi ekologis atau perilaku.
4.6 Menjalankan tes chi-square di R
R memiliki fungsi bawaan untuk tes chi-square, jadi kita dapat langsung menggunakan chisq.test() alih-alih menghitungnya secara manual:
Tangga Petunjuk: Jika Anda bingung cara menghitung Chi-square secara manual: - Petunjuk 1: Ingat formula: χ² = Σ(O - E)² / E - Petunjuk 2: Hitung frekuensi expected: E = (total baris × total kolom) / total keseluruhan - Petunjuk 3: Gunakan chisq.test() untuk hasil langsung
# Ekstrak statistik tes dan dfchi_stat <- chi$statisticdf_val <- chi$parameter# Buat nilai x untuk densitas chi-squarex <-seq(0, chi_stat +20, length.out =500)y <-dchisq(x, df = df_val)# Plotplot(x, y, type ="l", lwd =2, col ="#2171B5",ylab ="Density", xlab =expression(chi^2),main =paste("Distribusi Chi-Square (df =", df_val, ")"))# Tambahkan garis vertikal di statistik tesabline(v = chi_stat, col ="#c02728", lwd =2, lty =2)# Anotasitext(chi_stat +2, max(y)*0.8,labels =paste0("X² = ", round(chi_stat, 2)),col ="#c02728")